
나의 작은 valley
[NLP] 딥러닝 기반 자연어처리 본문
Sequence-to-sequence
:자연어처리 모델은 기본적으로 입력된 시퀀스(문장)을 다른 시퀀스로 변환하는 모델로, 인코더와 디코더로 이로워져있다. 그 사이에 존재하는 Context vector엔 입력된 문장의 특징들을 잘 요약한 값들이 벡터 형태로 존재한다. 인코더와 디코더를 구성하는 대표적인 모델인 RNN, LSTM, GRU를 알아보자. GRU의 경우 한국인이 개발을 해서 K-RNN 이라고 부르기도 한다. (펄럭)
RNN
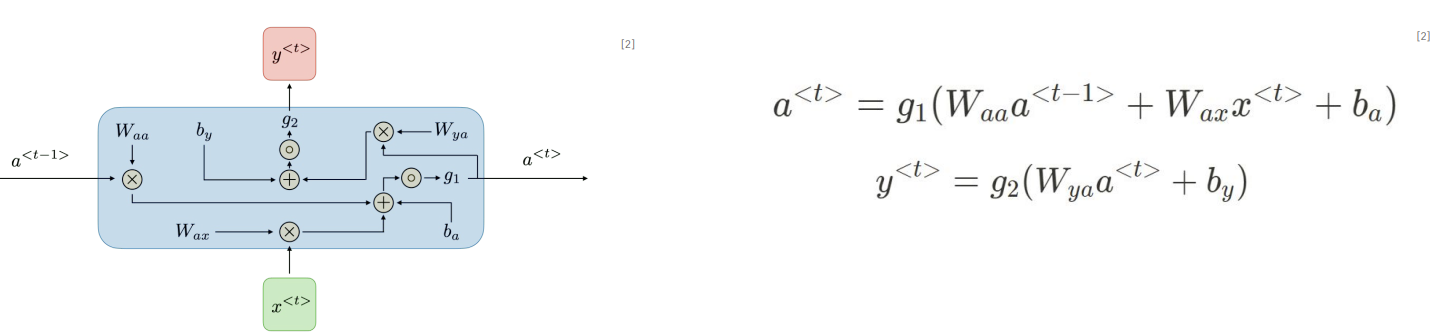
a<t-1>는 직전 hidden state를 의미한다. 마치 컴퓨터의 메모리와 같은 기능을 수행한다. 즉 이전 시간 단계의 정보를 가지고 있으며 이를 a<t>, 현재에 전달한다. x<t>는 현재 입력 정보, y<t>는 현재 출력 정보, g는 activation_function이다. 오른쪽 수식이 어려워보이지만 선형 방정식임을 자세히 보면 알수 있다.
-loss fuction
loss 값을 구하는 기준은 y<t>와 y<t> 예측값 간의 차이이다. 시계열(serial) 데이터 특성 상 순서가 중요한데 gradient update 과정을 그래서 Backpropagation through time(시간 순서 역전파)라고 부른다.
-입출력의 형태
: 기본적으로 다음 4가지의 형태로 입력값과 출력값이 올 수 있다.
1) one to one : ex) 분류 task
2) one to many : ex) 이미지 캡셔닝
3) many to one : ex) 감정 분석
4) many to many : ex) 번역
-장단점
pros) 모든 길이의 sequence 입력 가능.
cons) 병렬 처리가 불가능해서 느리다. activation 으로 tanh를 사용하기 때문에 gradient vanishing problem이 발생한다. (long-term-dependency)
-구현
class SimpleRNN(nn.Module): # SimpleRNN 클래스 선언
def __init__(self, n_inputs, n_hidden, n_outputs):
super(SimpleRNN, self).__init__() # nn.Module의 초기화 함수 상속
self.M = n_hidden # 은닉 상태(hidden state)의 크기를 지정
self.D = n_inputs # 입력 차원의 크기 지정
self.K = n_outputs # 출력 차원의 크기 지정
self.rnn = nn.RNN( # RNN 모듈을 생성
input_size=self.D, # 입력 차원의 크기 지정
hidden_size=self.M, # 은닉 상태의 크기 지정
nonlinearity='tanh', # 활성화 함수로 tanh를 사용
batch_first=True) # 배치 차원이 먼저 오도록 설정
self.fc = nn.Linear(self.M, self.K) # 출력을 위한 선형 변환을 정의
def forward(self, X): # 순전파 함수를 정의
# initial hidden states
h0 = torch.zeros(1, X.size(0), self.M).to(X.device) # 초기 은닉 상태를 0으로 설정
# get RNN unit output
out, _ = self.rnn(X, h0) # RNN에 입력을 전달하고 출력을 받음
# we only want h(T) at the final time step
out = self.fc(out[:, -1, :]) # 마지막 시간 단계의 출력만 사용하여 선형 변환을 수행
return out-학습
model = SimpleRNN(n_inputs=2, n_hidden=20, n_outputs=2).to(device) # SimpleRNN 모델을 생성하고, GPU로 전송
criterion = nn.CrossEntropyLoss() # 손실 함수로 CrossEntropyLoss를 사용
optimizer = torch.optim.Adam(model.parameters()) # 최적화 알고리즘으로 Adam을 사용
# 더미 입력 데이터 예제
inputs = torch.from_numpy(np.array([[[1, 2], [3, 4], [5, 6]]], dtype=np.float32)).to(device)
for epoch in range(300): # 300번의 에폭 동안 학습을 진행
model.zero_grad() # 기울기를 0으로 초기화
outputs = model(inputs) # 모델에 입력을 전달하고 출력을 받음
loss = criterion(outputs, torch.tensor([1]).to(device)) # 더미 타겟 데이터로 손실(loss)을 계산
loss.backward() # 역전파를 통해 기울기를 계산
optimizer.step() # 최적화 알고리즘을 통해 파라미터를 업데이트
if (epoch+1) % 30 == 0: # 30 Epoc마h다 손실을 출력
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 300, loss.item()))LSTM(Long-Short term memory)
:위에 언급한 RNN의 단점을 해소하기 위해 만들어진 모델이다. cell state와 input,ouput,forgot gate를 가지고 와서 만들어졌으며 이들의 기능을 비유적으로 설명하자면 중요한 부분을 더 잘 기억하고 비교적 중요하지 않은 부분을 덜 기억하도록 해서 gvp을 해소한다.

-구현
class LSTM(nn.Module): # LSTM 클래스 선언
def __init__(self, n_inputs, n_hidden, n_outputs):
super(LSTM, self).__init__() # nn.Module의 초기화 함수 상속
self.D = n_inputs # 입력 차원의 크기 지정
self.M = n_hidden # 은닉 상태(hidden state)의 크기를 지정
self.K = n_outputs # 출력 차원의 크기 지정
self.lstm = nn.LSTM( # LSTM 모듈을 생성
input_size=self.D, # 입력 차원의 크기 지정
hidden_size=self.M, # 은닉 상태의 크기 지정
batch_first=True) # 배치 차원이 먼저 오도록 설정
self.fc = nn.Linear(self.M, self.K) # 출력을 위한 선형 변환을 정의
def forward(self, X): # 순전파 함수를 정의
h0 = torch.zeros(1, X.size(0), self.M).to(X.device) # 초기 은닉 상태를 0으로 설정
c0 = torch.zeros(1, X.size(0), self.M).to(X.device) # LSTM의 초기 cell state를 0으로 설정
# get RNN unit output
out, _ = self.lstm(X, (h0, c0)) # LSTM에 입력을 전달하고 출력을 받음(hidden, cell)
# we only want h(T) at the final time step
out = self.fc(out[:, -1, :]) # 마지막 시간 단계의 출력만 사용하여 선형 변환을 수행
return outGRU
: LSTM이 생긴게 너무 복잡해서 만들어진 모델이다. 기존에는 2개의 state(hidden, cell)를 사용했다면 hidden state 1개만을 사용하고 gate도 update/reset gate 2개만을 사용한다.
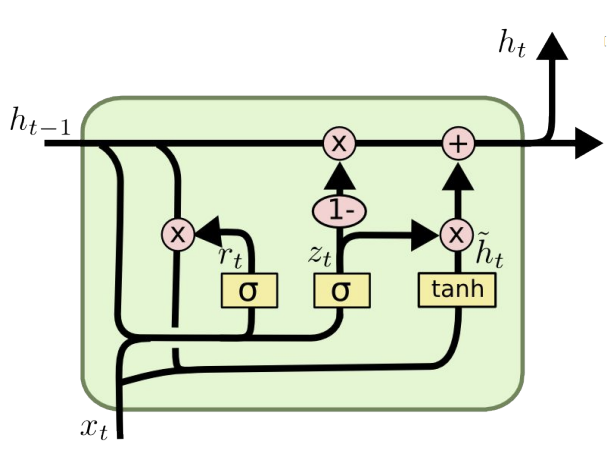
-구현
def forward(self, X)에서 아래의 코드만 바뀜.
out, _ = self.gru(X, h0) # GRU에 입력을 전달하고 출력을 받음 *간결 포인트RNN,LSTM,GRU

'Computer Science > [인공지능]' 카테고리의 다른 글
| [NLP] 자연어처리 pipline (0) | 2024.05.15 |
|---|---|
| [NLP] Attention (0) | 2024.05.10 |
| [NLP] 자연어 처리의 역사 (0) | 2024.05.08 |
| [NLP] 텍스트 전처리 (0) | 2024.05.07 |
| [NLP] 자연어처리란 + 기초 언어학 (0) | 2024.05.05 |

