
나의 작은 valley
[Generation] 생성 모델 역사/평가지표 본문
2013년 이전
: 주어진 데이터셋의 확률 분포를 학습(Likelihood)해서 새로운 데이터를 생성
2014년 ~
: 딥러닝 기반의 생성 모델의 등장과 발전
변분 오토 인코더-> GAN -> DM(확산 모델 *현재 주류 모델)
최대 가능도 추정법(maximum likelihood Estimation, MLE)
: 출력된 결과물들을 바탕으로 모델 파라미터를 역으로 추정하는 것을 Likelihood라고 한다.
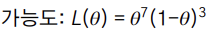
ex) 동전을 던졌을 때 앞면이 7번 뒷면이 3번 나온 상황에서 MLE를 구해보면 다음과 같다.

cf) 앞면이 나올 확률은 0.5%이다. 즉 표본을 키우는 것의 중요성을 알 수 있다.
생성 모델의 학습
: 쿨백-라이블러 발산
KL(p(x) || g(x)) = \sigma p(x) log ( p(x) / g(x) ) , 두 분포 p(x), g(x) 간의 차이가 낮아질 수록 낮아진다.
-> 즉 두 분포가 유사해지는 방향으로 최적화를 하는 것이 목표.
생성 모델의 평가지표 필요성
판별 모델의 경우) GT가 존재 -> 명확한 오차값을 구하는 것이 가능.
생성 모델의 경우)
-> 사람이 생성된 이미지에 대해서 평가를 내린다면 '주관'이 반영될 여지가 많음.
-> 의료 이미지의 경우 labeling 과정과 비용이 비싸다.
[생성 모델의 조건]
1) 주관이 개입될 여지가 낮아야 한다. 2) 품질(Fidelity)이 높아야 한다. 3) 다양성이 확인되어야 한다.
Inception Score (IS)
예리함(Sharpness)과 다양성(Diversity) 두 가지를 고려하는 평가지표.

예리함을 측정하는 방법)
- 생성된 이미지를 분류기에 넣었을 때 제대로 인식된다면 좋은 예리함을 가진 데이터를 생성한 것.
다양성을 측정하는 방법)
- 생성된 이미지들의 분포가 다양하면 다양성이 높은 모델을 만든 것.
IS 한계점)
- 클래스 구분이 불가능한 경우 평가가 불가능하다.
ex) 이미지 생성
Fréchet Inception Distance (FID)
: 훈련 데이터와 생성 데이터의 각 분포를 정규 분포로 가정하고 확률 벡터가 아닌 특징(feature) 벡터를 사용하여 두 분포의 거리를 계산한다. (낮을수록 좋음.)
FID 한계점)
: Fidelity가 강조된 모델인지, Diversity가 강조된 모델인지 알 수 없다. 즉 두 지표를 각각 측정할 수 없다.
Precision & Recall
판별 모델에서)
- precision = 진짜 postive(TP) / Postive로 예측(TP + FP)
- recall = 예측 결과가 실제 postive (TP) / 실제로 postive (TP + FN)
생성 모델에서)
- precision = 생성된 데이터 중에서, 실제 데이터 분포에 아주 가까운 데이터
- recall = 실제 데이터 중에서, 생성된 데이터 분포에 아주 가까운 데이터
"가까운(close to)" 의미)
: 생성/실제 데이터 중 하나와 가장 '가까운' 데이터를 의미한다. 이떄 가깝다의 정의는 다음 그림과 같다.

즉, 반지름 범위 내에 존재하면 근방 데이터로 간주한다.
precision 계산)

원은 real_data이고 네모는 fake_data이다. 가까운 fake 데이터 개수 / fake 데이터 전체 개수 = 1/4
recall 계산)

가까운 real 데이터 개수 / real 데이터 전체 개수 = 4 / 4
한계점) 이상치에 민감함. embedding이 조금만 바뀌어도 값이 확 바뀐다.
-> 단순한 반경의 합집합이 아니라 가중 합집합으로 계산하여 이상치에 대한 민감도를 줄일 수 있다.(Density)
cf) diversity-guality는 trade off 관계에 있다.(반비례)
cf) coverage : recall을 대체할 수 있는 값
-> 생성된 데이터에 대해 매번 거리를 계산하지 않고 실제 데이터 집합으로 계산하여 안정적이고 계산량을 감소할 수 있다.

-> coverage는 real data의 manifold에 속하는 생성 데이터(fake data)를 말하는 것 같고 precision은 real data의 manifold에 생성된 데이터(fake data) 수 / 전체 생성 데이터(fake data) 수
CAS(Classification Acc Score)
: 생성 모델이 만든 이미지를 데이터 샘플로 간주한다. 샘플 데이터들을 분류기에 넣고 클래스를 예측한다. 이때 일치비율이 높을수록 괜찮은 그림을 만들었다는 평가를 내린다.
cf) 분류기를 모델마다 학습시켜야 한다는 단점이 있다.
LPIPS(Learned Perceptual Image Patch Simlarity)
: 특징 비교를 통한 유사도 측정 기법을 의미한다.
-> 생성된 이미지 간의 LPIPS가 낮아도 diversity가 높다고 해석할 수 있다.
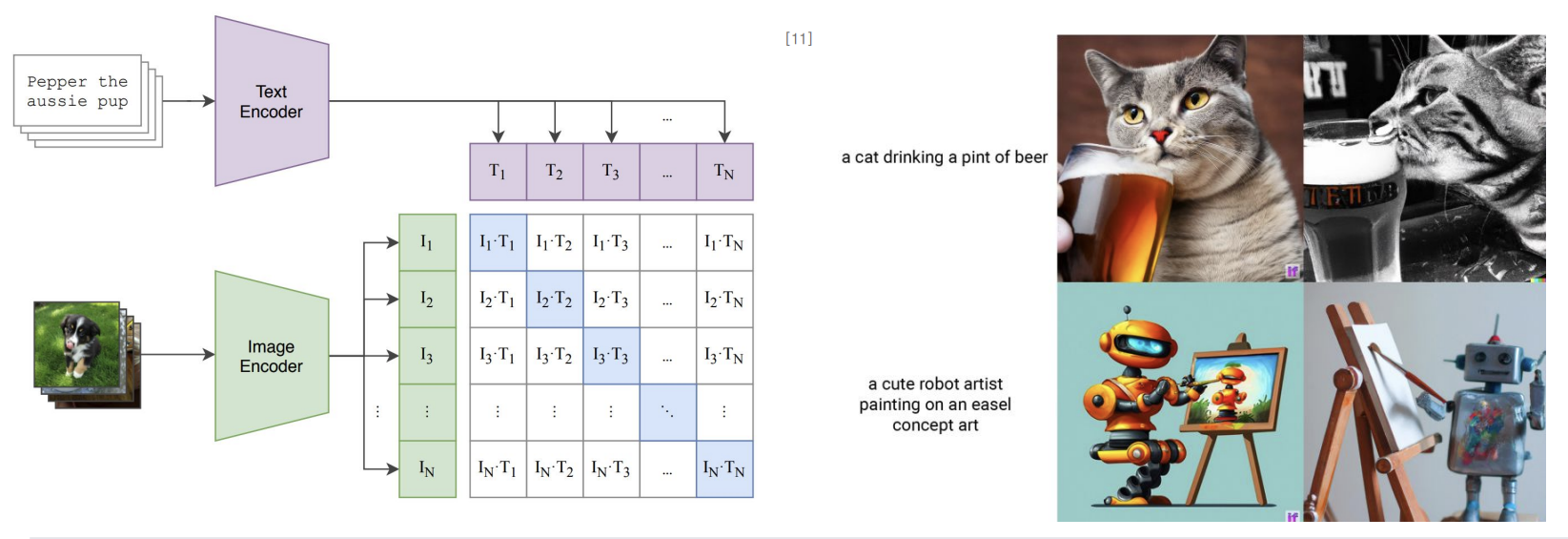
CLIP Score
: test-image 관계에 대한 평가 지표로 둘의 관계를 학습한 CLIP를 특징 추출기로 활용하여 유사도를 측정한다. 즉 문장들의 특징과 이미지의 특징 간의 유사도를 확인하는 것이다.
'Computer Science > [인공지능]' 카테고리의 다른 글
| [NLP] 자연어처리란 + 기초 언어학 (0) | 2024.05.05 |
|---|---|
| [Generation] 생성 모델의 변천 (0) | 2024.05.05 |
| [Computer Vision] Ch 5 ~ Ch 8 (1) | 2024.04.12 |
| [ComputerVision] ch 1 ~ ch 4 (0) | 2024.04.05 |
| [딥러닝] DNN 구현 (0) | 2024.03.15 |



